-
This is the simplest need from an application perspective:

-
Here we just wrap custom code with a schema validate on the input and output.
XML Processing Models & Pipelines
R. Alexander Milowski
milowski@sims.berkeley.edu
School of Information Management and Systems
#1
Processing Models
Efficient XML Processing is non-trivial.
Many specifications are about getting XML to the "doorstep" of your application.
They aren't about how you process them component by component.
There are lots of component specifications:
XML Schema
XSLT, XPath, XML Query
XPointer, XLink
XML Base, XInclude
SOAP
etc.
#2
Always a Multistep Process
Processing XML is always multi-step.
For example:
Parse XML
Validate XML w/ Schema
Use XML
Throw in a transformation or two...
...and you get a mess.
#3
Application Needs
What is needed is a specification of the processing model.
Something that applications can use to efficiently organize these steps.
Something that vendors can use to design infrastructure for application builders.
Many people call these "pipelines".
#4
Pipelines
This paper is really the first instance of this idea:
D. McKelvie, C. Brew, and H. Thompson. Using SGML as a Basis for Data-Intensive NLP. In Proceedings of the fifth Conference on Applied Natural Language Processing (ANLP-97) 1997
Here's that article: anlp97.pdf
The pipes are "fat" because they pass XML between components.
Definition: A pipeline is a chaining of XML-in-XML-out components.
Note: The chaining doesn't have to be a simple "line" components strung output-to-input.
#5
Pipeline Example 1
This is the simplest need from an application perspective:
Here we just wrap custom code with a schema validate on the input and output.
#6
Pipeline Example 2
Here we chain together "simple" transformations:

#7
A "Real" Pipeline
This converts my "mathdoc" documents into latex:

I need multi-step pipelines to deal with escaping of characters and unicode.
I need two outputs since my citations need to be in a separate input file for latex.
#8
Possible Pipeline Components
XInclude, XML Base
XML Schema, Relax NG, Schematron
XSLT, XPath Filtering, XML Query
"micro operations": Element/attribute elimination, Element/attribute value setting, etc.
#9
Sun Pipeline Language
Sun authored a specification language for pipelines.
Its an XML document that describes the flow.
You can see the note at: http://www.w3.org/TR/xml-pipeline/
More information is available at Sun's website.
#10
An Example:
Here's an example from their web page:
<pipeline xmlns="http://www.w3.org/2002/02/xml-pipeline"
xml:base="http://example.org/">
<param name="target" select="'result'"/>
<processdef name="xinclude.p" definition="org.example.xml.Xinclude"/>
<processdef name="validate.p" definition="org.example.xml.XmlSchema"/>
<processdef name="transform.p" definition="org.example.xml.XSLT"/>
<process id="p1" type="xinclude.p">
<input name="document" label="myfile.xml"/>
<output name="result" label="xresult"/>
</process>
<process id="p2" type="validate.p">
<input name="document" label="xresult"/>
<input name="schema" label="someschema.xsd"/>
<output name="result" label="valid"/>
<error name="invalid" label="#invalidDocument"/>
</process>
<process id="p3" type="transform.p">
<input name="stylesheet" label="mystyle.xsl"/>
<input name="document" label="valid"/>
<output name="result" label="result"/>
<param name="chunk">0</param>
</process>
<document name="invalidDocument">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Failure!</title>
</head>
<body>
<h1>Your job failed because the document is invalid.</h1>
</body>
</html>
</document>
</pipeline>
#11
Processors
A processor is declared by the pipeline.
Syntax:
<p:processdef name = xs:ID definition = xs:string />
The 'definition' attribute value is implementation defined.
You use this to declared your XSLT, XML schema, etc. implementations.
#12
Steps
Steps are represented by 'process' elements.
Syntax:
<p:process id = xs:ID type = xs:IDREF ignore-errors = xs:boolean > <!-- Content: ( p:input | p:output | p:error | p:param | foreign-content )* --> </p:process>
Each process can specify inputs and outputs.
#13
Inputs and Outputs
Inputs are matched to outputs by labels.
If inputs aren't files, then they should be the output of some process.
This is like make or ant.
#14
Latex Example
My latex pipeline:
<pipeline xmlns="http://www.w3.org/2002/02/xml-pipeline"
xml:base="http://example.org/">
<param name="target" select="'result'"/>
<processdef name="filter.p" definition="org.mathdoc.tools.FilterUnicode"/>
<processdef name="validate.p" definition="org.example.xml.XmlSchema"/>
<processdef name="transform.p" definition="org.example.xml.XSLT"/>
<process id="m1" type="validate.p">
<input name="document" label="mydoc.xml"/>
<input name="schema" label="mathpaper.xsd"/>
<output name="result" label="valid"/>
<error name="invalid" label="#invalidDocument"/>
</process>
<process id="m2" type="transform.p">
<input name="stylesheet" label="paper2tex.xsl"/>
<input name="document" label="valid"/>
<output name="result" label="texresult"/>
<param name="chunk">0</param>
</process>
<process id="m3" type="filter.p">
<input name="document" label="texresult"/>
<output name="result" label="filtered"/>
</process>
<process id="m4" type="transform.p">
<input name="stylesheet" label="finalsyntax.xsl"/>
<input name="document" label="filtered"/>
<output name="result" label="mydoc.tex"/>
</process>
<process id="b1" type="transform.p">
<input name="stylesheet" label="paper2bib.xsl"/>
<input name="document" label="valid"/>
<output name="result" label="bib-texresult"/>
<param name="chunk">0</param>
</process>
<process id="b2" type="filter.p">
<input name="document" label="bib-texresult"/>
<output name="result" label="mydoc.bib"/>
</process>
<document name="invalidDocument">
<error>
Your document is not valid!
</error>
</document>
</pipeline>
#15
Cocoon Pipelines
Cocoon pipelines are chains of SAX handlers.
This means each component is intimately intertwined with the next!
But you can do alot of things very efficiently this way:
The implementation is streaming.
Low memory consumption.
Faster response times.
#16
Event Application Example
The basic pipeline architecture:
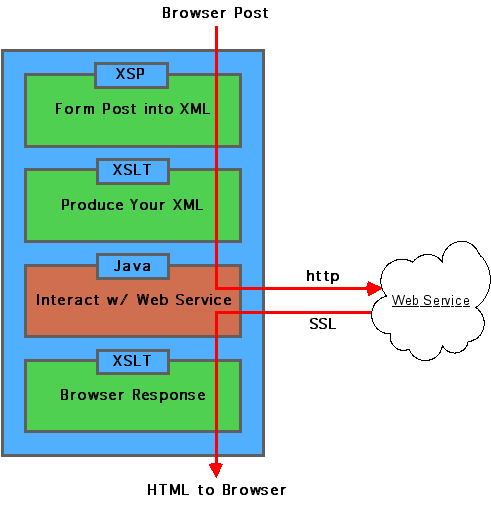
#17
Event Application Example - Syntax
Here's the configuration in the sitemap:
<map:match pattern="*.post">
<!-- generate XML from the form data -->
<map:generate type="serverpages" src="form-result.xsp"/>
<!-- Process the form into a app-specific format -->
<map:transform src="{1}.post2xml.xsl"/>
<!-- Handle any web service specifics -->
<map:transform src="{1}.pre-service.xsl"/>
<!-- Talk to the web service. This is a custom CDE component that was
built to allow Cocoon to serialize the content in the pipeline to
a web service connection and the parse the response. -->
<map:transform type="webservice">
<map:parameter name="url" value="http://localhost:8080/webservice/event.service"/>
</map:transform>
<!-- Here we have the response from the web service in the pipeline. -->
<!-- Decode the response -->
<map:transform src="{1}.post-service.xsl"/>
<!-- Format the result for the browser -->
<map:transform src="{1}.final.xsl"/>
<!-- Serialize to the waiting browser connection.-->
<map:serialize type="xhtml"/>
</map:match>
#18
Other Pipeline Implementations
NetKernel from 1060 Research - REST-based services - http://www.1060research.com
Orbeon - http://www.orbeon.com/
Markup Technology - http://www.markuptechnology.com
See also: XML 2003: Re-interpreting the XML Pipeline Note by Henry Thompson
This list is not exhaustive!