|
|
Lecture 1: Motivation, History, Basics of XML, Unicode, and Infosets
R. Alexander Milowski
milowski@sims.berkeley.edu
School of Information Management and Systems
#1
Motivation
Markup systems for annotating text for formatting and other purposes have existed since the 60's but most were Procedure Markup systems.
Procedural Markup tells the application what to do with the information and not what the information represents.
Motivation: "Procedural markup is also inflexible. If the user decides to change the style of his document (perhaps because he is using a different output device), he will need to repeat the markup process to reflect the changes." [1]
The first "logical document model" system was Scribe (c. 1980) [2]
Philosophy: Markup should be descriptive and describe the logical structure of the information (document) and not its particular use or format.
[1] http://www.sgmlsource.com/history/AnnexA.htm
[2] B. Reid, "Scribe: A Document Specification Language and its Compiler," Ph.D. Dissertation, Carnegie Mellon University, Pittsburgh, PA (October, 1980).
#2
History of XML
XML's Development start around 1996.
The motivation was in part due to the success of HTML and in part due to the crushing need to simplify SGML.
Jon Bosak from Sun Microsystems was the prime motivator for the creation of XML and inspired by Yuri Rubinsky's[1] "SGML on the Web"
The W3C (World Wide Web Consortium) was chosen to host the standards process and the original XML Committee was formed.
The first draft was produced in November 1996 and shown at the SGML conference in Boston, MA in December 1996.[2]
In February 1998, XML became a W3C Recommendation[3].
There is now a "second edition"[4] and XML 1.1 is now a Candidate Recommendation[5].
[1] http://www.oasis-open.org/cover/yuriMemColl.html
[2] http://www.w3.org/TR/WD-xml-961114.html
[3] http://www.w3.org/TR/1998/REC-xml-19980210
[4] http://www.w3.org/TR/1998/REC-xml
[5] http://www.w3.org/TR/xml11/
#3
The W3C Process
Interest in a particular topic is made known by the consortium members either as a result of a published note or from the results of a workshop.
Either a Working Group is formed or the topic is assigned to an existing group.
A Requirements Document is drafted and approved by the first the working group and then the consortium.
All documents go through these stages: Initial Draft, Working Draft, Last Call Draft, Proposed Recommendation,and Recommendation.
#4
What is XML?
XML is about encoding and structuring single "instances" of documents.
XML and related standards also define "what is a valid instance".
XML is not a programming language. It has NO SEMANTICS.
Erase "XML Programming" from your vocabulary.
#5
What is Document?
Document
1 a archaic : PROOF, EVIDENCE b : an original or official
paper relied on as the basis, proof, or support of something c :
something (as a photograph or a recording) that serves as evidence
or proof 2 a : a writing conveying information b : a material
substance (as a coin or stone) having on it a representation of
thoughts by means of some conventional mark or symbol c :
DOCUMENTARY [1]
Documentary
1 : being or consisting of documents : contained or certified
in writing <documentary evidence> 2 : of, relating to, or
employing documentation in literature or art; broadly : FACTUAL,
OBJECTIVE [1]
Markup Language
: a system (as HTML or SGML) for marking or tagging a
document that indicates its logical structure (as paragraphs) and
gives instructions for its layout on the page for electronic
transmission and display [1]
[1] Merriam-Webster Online: http://www.m-w.com/
#6
What is an XML Document?
It can be thought of as a tree of elements--containers of information.
Traditionally, from a markup perspective:
Articles, books, notes, poems, novels
Technical manuals, slip sheets, product packaging
More abstractly, documents are instances of information that typically have structure.
So, lots of things are documents:
Messaging, e-mails, web sites, etc.
Business transactions, invoices, statements, etc.
Log files, configuration files, install scripts, etc.
Ontologies, medical lab data, instrument experiment results, human genome annotations, etc.
XML is a useful common syntax for encoding these documents.
#7
The Real Answer
Documents are instances of units of information*.
* With XML you get to define "instance", "unit", and "information".
#8
What XML Provides
Internationalization via Unicode
Validation of instances.
Localization of names via namespaces (e.g. My 'tomato' isn't your 'tomato').
A "human readable" format.
Hierarchical structure.
A "motif" for extensibility.
#9
An Example
<slide>
<title>What XML Provides</title>
<contents>
<ul>
<li><p>Internationalization via Unicode</p></li>
<li><p>Validation of instances.</p></li>
<li><p>Localization of names via namespaces
(e.g. My 'tomato' isn't your 'tomato').</p>
</li>
<li><p>A "human readable" format.</p></li>
<li><p>Hierarchical structure.</p></li>
<li><p>A "motif" for extensibility.</p></li>
</ul>
</contents>
</slide>
#10
A More Complicated Example
<c:pseudocode name="Adj">
<args><arg>v</arg><arg>j</arg></args>
<c:for>
<c:varassign>
<c:var>i</c:var>
<c:constant>1</c:constant>
</c:varassign>
<to><c:constant>j</c:constant></to>
<c:do>
<c:varassign>
<c:var>r</c:var>
<c:func name="find-simplex">
<c:value><c:var>v</c:var></c:value>
<c:value><c:var>i</c:var></c:value>
</c:func>
</c:varassign>
</c:do>
</c:for>
<c:return><c:value><c:var>r</c:var></c:value></c:return>
</c:pseudocode>
|
Adj(v, j): for i ← 1 to j do r ← find-simplex(v,i) return r |
#11
XML Document Structure
|
|
#12
Reading EBNF
[22] prolog ::= XMLDecl? Misc* (doctypedecl Misc*)?
[23] XMLDecl ::= '<?xml' VersionInfo EncodingDecl? SDDecl? S? '?>'
[24] VersionInfo ::= S 'version' Eq ("'" VersionNum "'" | '"' VersionNum '"')
[25] Eq ::= S? '=' S?
[26] VersionNum ::= ([a-zA-Z0-9_.:] | '-')+
[27] Misc ::= Comment | PI | S
'+' means 'one or more', '?' means 'optional', '*' means 'zero or more'.
Parenthesis group constructs.
'|' (pipe character) means 'or'
'string' means the occurrence of the literal string.
[c-c] is a character class and represents a single character in the specifed range.
#13
Getting Started
An XML document is stored as a Unicode encoded data stream (more on this later).
Any text editor will do, but the encoding must support the characters used.
Every document should start with an "XML Declaration" but it isn't required.
#14
The XML Declaration
The XML Declaration must be at the exact start of the document (i.e. no whitespace leading the declaration).
It consists of three parts specified by pseudo-attributes:
version='n.n' -- specifies version information (e.g. "1.0").
encoding='type' -- specifies the unicode encoding used by this "data stream" to encode the unicode characters of the XML document.
standalone='yes|no' -- a specification of whether the document is sufficiently contained in the current character stream.
An example:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
#15
The Prolog & Epilog
Both the prolog and epilog may contain:
Comments
Processing Instructions
Whitespace (e.g. Space characters, tabs, any Unicode whitespace character )
The only constraint is that the XML Declaration must be first in the prolog.
#16
Elements
Elements consist of a start tag (e.g. "<start>"), its contents, and an end tag (e.g. "</start>").
The contents of an element are ordered.
Start tags can have attributes -- name/value pairs (e.g. "<start kind="slow"/>).
Elements must be well-formed: balanced, conforming syntax, attributes are valid, no duplicates, etc.
<top>
<next>
<bottom> ... </bottom>
</next>
</top>
(more will be said about well-formed later).
The element name must conform to:
[5] Name ::= (Letter | '_' | ':') (NameChar)*
#17
Empty Elements
Elements can be empty.
They have no content but can have attributes.
They have a special syntax:
<nothing/> <almost-nothing but="something"/>
#18
Attributes
Attributes are only associated with the start tag.
They contain "simple" text content -- no elements.
They are unordered and you may not have attributes with the same name on an element.
Special characters must be escaped (e.g. '<' must be escaped as < -- see next slide)
Syntax: name='value' or name="value"
The name conforms to the same constraints as an element name.
<doc status='final'> <author href="http://www.milowski.com">Alex Milowski</author> </doc>
#19
Text and Characters
Text is allowed within an element and as the value of an attribute.
Some characters must be escaped: '&' and '<'
An entity reference allows you to escape these characters: & <
These are pre-defined:
| Character | Entity Reference |
|---|---|
| & | & |
| < | < |
| > | > |
| ' | ' |
| " | " |
#20
General Entities
General entities are a somewhat arcane way of "including text".
Similar things can now be accomplished by use of the XInclude last-call draft[1].
But if you insist, you can declare them:
<!ENTITY mystuff "Here's some replacement text">
and then use it:
<p>After this I'll get my text: &mystuff;</p>
but it requires putting the declaration into the "internal subset of the document type declaration"--which we aren't going to dig too deep into.
[1] http://www.w3.org/TR/xinclude/
#21
Comments
You can put comments in the prolog, epilog, and as content of an element.
Syntax:
[15] Comment ::= '<!--' ((Char - '-') | ('-' (Char - '-')))* '-->'
That is, a comment contains text except that '--' is not allowed.
Example:
<!-- Where or where did my content go? -->
Not allowed:
<!-- bad comment -- bad! -->
#22
Processing Instructions
Processing Instructions are like comments accept they are meant for application-specific processing.
Syntax:
[16] PI ::= '<?' PITarget (S (Char* - (Char* '?>' Char*)))? '?>'
[17] PITarget ::= Name - (('X' | 'x') ('M' | 'm') ('L' | 'l'))
That is, a processing instruction contains text except that '?>' is not allowed in the content and 'xml' is not allow in the name.
Example:
<?insert 5/10/03?>
Not allowed:
<?very ?> bad ?>
But the W3C can break the rules:
<?xml-stylesheet href="mystyle.xsl"?>
#23
CDATA Sections
A CDATA section marks text as "just text".
Element-like syntax will be ignored.
Syntax:
[18] CDSect ::= CDStart CData CDEnd [19] CDStart ::= '<![CDATA[' [20] CData ::= (Char* - (Char* ']]>' Char*)) [21] CDEnd ::= ']]>'
That is, a CDATA section contains text except that ']]>' is not allowed in the content.
Example:
<![CDATA[<greeting>Hello, world!</greeting>]]>
This generates the text '<greeting>Hello, world!</greeting>' and not the element 'greeting'.
#24
DTDs and Document Types
A DTD (Document Type Definition) defines the rules for what elements and attributes may contain and for what attributes an element may have.
There are complicated "text" semantics for processing DTD modules and expanding entity references.
But, they aren't that hard to read:
<!ELEMENT img EMPTY>
<!ATTLIST img
src CDATA #REQUIRED
>
<!ELEMENT p (#PCDATA|img|b|i)* >
<!ELEMENT b (#PCDATA) >
<!ELEMENT i (#PCDATA) >
#25
Associating DTDs with Documents
Just before the document element, you associated the document with the DTD:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html> ... </html>
You can also just inline the declarations:
<!DOCTYPE simple [ <!ELEMENT simple (#PCDATA)> ]> <simple>Super!</simple>
The example above is called the "internal subset".
The "internal subset" is where you put general entity declarations.
#26
Eh?
You can read more about DTDs in any basic XML book (e.g. Learning XML) and in the XML Recommendation (one of your reading assignments).
We're going to be doing schemas... so don't sweat it.
But, they are out there and in use. Knowing the basics won't take long.
#27
Characters and Unicode
All text, names, values, syntax, etc. in an XML document are Unicode Characters.
Unicode assigns each character a "code point"--a number and arranges these code points into code blocks.
The familiar ASCII is the first code-block (e.g. decimal 65 is the letter 'A')
Unicode attempts to represent all languages with code blocks and code points.
Code points also have properties like: 'whitespace character' or 'name character'.
The Greek Code Page: Ux0370
#28
Unicode in XML
Unicode characters can either be encoded directly in the document or accessed by reference.
You need a unicode-aware editor to encode them directly and then you just type in the character you want.
Otherwise you use a character entity reference:
[66] CharRef ::= '&#' [0-9]+ ';'
| '&#x' [0-9a-fA-F]+ ';'
An example, some mathematics:
∀α∈Γ(...) ∀α∈Γ(...) |
∀α∈Γ(...) |
#29
Whitespace Handling
Often, whitespace (space characters, newlines, tabs, etc.) are added to make the XML more "readable".
Whitespace can be marked as not significant and the XML Processor will convey that to the application.
An attribute xml:space can be added to any element to control this behavior.
A value of 'default' means that a validating processor can mark whitespace as ignorable.
A value of 'preserve' means it is significant.
Note that you need to validate to have ignorable whitespace. To get this from an XML Processor you must have a DTD.
#30
Parsing and Applications
An XML Processor is a component that parses the XML syntax and reports on its content and conformance to an application.
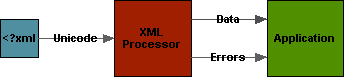
An XML Processor
When there are fatal errors the processor isn't allowed to "report data" in a "normal way".
#31
Well Formed vs. Valid
A well-formed document is balanced and syntactically correct.
It isn't necessary that all the "parts" to a well-formed document were found (e.g. external references, DTDs, etc.)
A valid document has had all its parts verified and conforms to a DTD.
Validating can mark ignorable whitespace and default attribute values.
In contrast, schemas have their own definition "validity" since their process comes after validation by an XML processor.
#32
What is XML to an Application?
Syntax? Passing "<tag>" and "</tag>"?
Names and Values? Passing start "tag" and end "tag"?
Whitespace? Text? Is there a difference?
How about comments, processing instructions, attributes, etc?
Is it an API? (SAX - Simple API for XML)
#33
Information Sets (infosets)
We really don't want syntax--that's too much.
But, a lot of the rest we do want (e.g. the application needs to decide when whitespace is ignoreable and not text).
An XML Processor conveys an Information Set to the application:
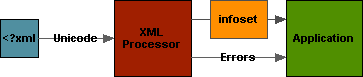
#34
The XML Infoset
From the standard:
"Its purpose is to provide a consistent set of definitions for use in other specifications that need to refer to the information in a well-formed XML document [XML].
It does not attempt to be exhaustive; the primary criterion for inclusion of an information item or property has been that of expected usefulness in future specifications. Nor does it constitute a minimum set of information that must be returned by an XML processor. "
An infoset is a hierarchy (or tree) of items with named properties.
Each property can have a simple value (e.g. a name, text, URI, etc.), other items as its value, or lists of either simple values or items.
#35
An Example Infoset Diagram
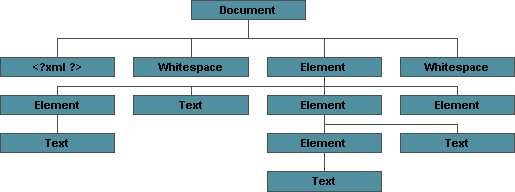
<?xml version="1.0"> <doc><title>My Document</title> <body><p>something</p> </body><citations/></doc>
#36
Document Info Item
[children] - An order list of child info items. There must be exactly one element info item amongst them. There are other constraints too...
[document element] - The element corresponding to the root of the element tree.
[base URI] - The base URI of this document.
[character encoding scheme] - The name of the unicode character encoding scheme used.
[standalone] - The standalone value from the xml declaration.
[version] - The version value from the xml declaration.
#37
Element Info Item
[local name] - The name of the element. Note: "local" will be discussed next time when we go over namespaces.
[children] - An ordered list of the children (elements, characters, comments, or processing instructions) info items.
[attributes] - An unordered list of attribute info items.
[base URI] - The base URI of the entity from which this element was parsed.
[parent] - The parent element or document info item.
#38
Attribute Info Item
[local name] - The name of the attribute.
[normalize value] - The value of the attribute as normalized by the XML Processor.
[owner element] - The element upon which this attribute was specified.
#39
Character Info Item
[character code] - The unicode character code (code point).
[parent] - The element containing this character
#40
There's More...
There are more properties than what has been show here.
There are info items for processing instructions, comments, and few more things.
Namespaces are amongst the things we'll handle next time.
The XML Information Set recommendation is one of your reading assignments.
#41
Information Sets are Extensible
New recommendations can associate properties with info items by adding properties.
For example, XML Schema adds properties to the infoset to record the results of validation.
Proprietary software can add their own properties too.
#42
Summary
We've covered:
XML Syntax
Unicode
XML Information Set
Next time: Namespaces, More Infosets, and XPath.
Questions?
