Version 1.0, DRAFT
26 February 2002
This paper presents of the Document Engineering perspective on e-business. It describes a roadmap or reference diagram upon which the various methods and skills of Document Engineering can be arranged. It introduces modeling and the role of methodologies with the goal of explaining the complementary methods of "document analysis" and "business process analysis" in the document engineering approach.
Document Engineering perceives the landscape of e-business to be comprised of documents and processes that produce and consume them -- static and dynamic components that together enable a business system. Documents exist in the real world as physical artifacts: application forms, registration processes, purchase orders, credit controls, and so on.
Documents and processes are symbiotic, mutually benefiting each other; they are the ying and the yang of electronic business.
When we first examine a business system, we study its existing or 'problem' state. This allows us to appreciate the nature of the system and its strengths and weaknesses. But to study something, we must abstract the real artifacts into things we can comprehend and manipulate. And in abstracting, we leave the real world and enter the artificial world of modeling.
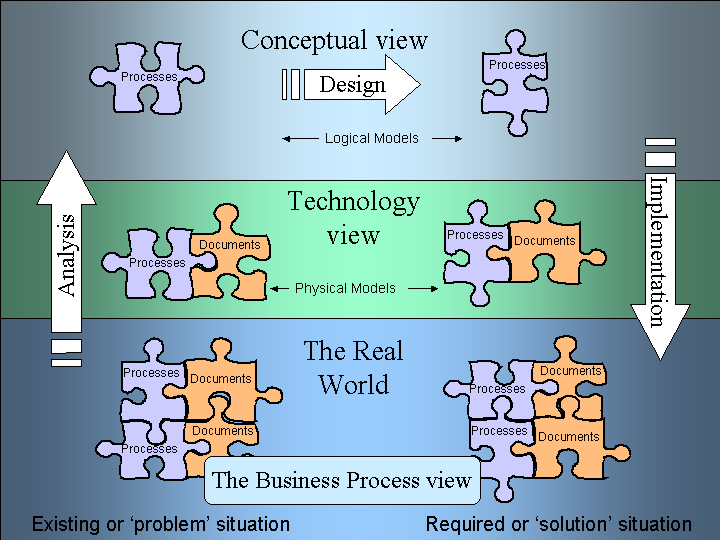
Figure 1 describes this abstraction. We start in the lower left corner, where the document and processes of the real world are abstracted into models of documents and process by the activity known as Analysis.
Figure 1. The Document Engineering Landscape
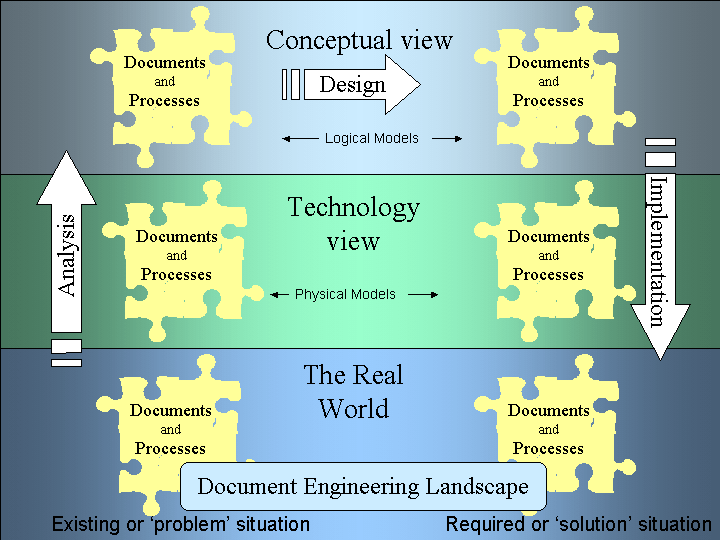
Analysis is the study of the real world artifacts. We analyze things by creating models. These may be mental image pictures, scale replicas or architectural diagrams. In Document Engineering we typically use some form of notation, such as diagrams, to describe our model of the system.
Initially these descriptions will be tightly coupled to the physical implementation. Often this will be influenced by the technology involved in its production. For example, if the printed document artifact we are analyzing has a three line address description, it seems natural to model this as three lines of address description. If the system defines a process known as "online application" and another as "offline application" we show these as separate processes.
The models that contain these technological constraints or features are the 'physical' models -- from 'physic', of nature. Physical models reflect the physical implementation of the documents or processes, the technology view. They show HOW things work.
Good analysis encourages us to look beyond the physical model, to ask WHY things work. This is the conceptual view. We see beyond the three line address description constraint -- we are interested in address descriptions as a concept. We do not differentiate between online and offline application. The fact that one uses a web form and the other a paper document is not important to the concept of application. We want to look at the concepts behind the process, to find out why is it doing these things. These are the 'logical' models -- from 'logos', to reason why. This change in modeling perspective is shown in Figure 1 as the arrow on the left that indicates a move to a higher layer of Analysis.
Experience tells us that defining these conceptual models is where we start to understand the true nature of the system. It is this understanding that leads to the possibility of improvement -- that is design. In Figure 1 this process is indicated by the arrow across the top of the diagram that depicts the Design process.
At several points during the construction of our analysis models a voice cries out "There must be a better way". When we study our logical model of the existing system we can start to formulate what that better way may be. This may mean removing redundant processes or data, re-using existing patterns of structure or activity, standardizing on one process or rationalizing a document's structure. We may design our address description to be expressed as room number, floor number, street number, building name and street name, because we have a requirement to re-use the address description in other processes (such as sorting) that require this finer granularity.
It is essential to treat analysis and design as two separate activities. Otherwise we are tempted to build the 'better way' into our models too early. This often leads to inaccurate representations of existing systems and therefore poorer ultimate designs. For example, if we had assumed that 'online' and 'offline' applications were the same processes during our analysis, we should have lost that differentiation and may not have recognized the need for different processes for each when we start to design a new system.
Having established a new logical model for our system, we have to recognize the constraints of the technology in which it will operate. We know WHAT we want, now we have to decide HOW it can be built. We move into the process of implementation (the arrow moving down the right side of Figure 1).
This phase may entail encoding the models into a computer language and inheriting the constraints that this environment places on the model. Perhaps our technology platform cannot store large binary images or we cannot define certain business rules within our language. Maybe the printed form now only allows two lines of street description. These factors must be accommodated in our new physical model. In an architect's plans, these would be the working drawings.
Finally, our designs for new documents and processes are purely theoretical unless we take them and put them in the real world. XML programmers can build stylesheets to transform our address description into two lines of text for the printed form and a different stylesheet for sorting by postal delivery. Programmers can write applications and administrators can create procedural manuals for online and offline application processing. Hopefully, we have arrived at our required solution.
Of course, this is a panoramic view. Sometimes analysis is all we do, sometimes we repeat the cycle, or jump in at points along the way. But now we have a landscape in which to place our activities.
We have discussed modeling and the role of methodologies. Let us now superimpose this onto our landscape to illustrate how document engineering can accommodate the use of methodologies.
The processes by which analysis, design and implementation are undertaken can be defined by formal steps of a methodology. This is shown against our 'landscape' in Figure 2.
Figure 2. What Methodologies Provide
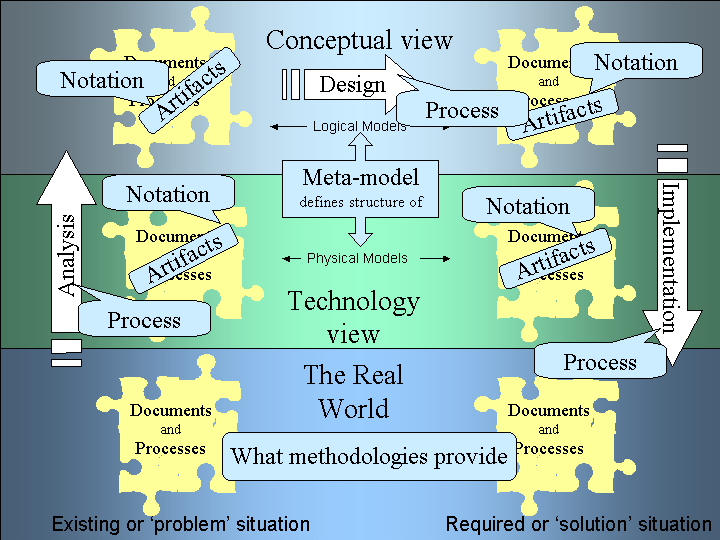
These methodologies may define a Meta-model. That is, a description of how to describe both the data and the processes of the system.
This Meta-model defines the model we use, but it is the Notation that presents them. These Notations can be diagrams, spreadsheets, text descriptions, or worksheets.
We should not forget that the collection of model Notations and other system documentation also form Artifacts -- reports, program specifications, procedure manuals and user guides. They are artifacts because the exist in the real world and representations of the models we abstracted. They are artifacts of the methodology. As proof that these are real artifacts, we could stand on a system specification report to reach on top of a shelf, but we cannot do this with the model of the system.
A related paper by Hayes & Glushko argues for an emphasis on modeling artifacts. This emphasis is repeated in this and is shown graphically in Figure 3.
Figure 3. The Artifact View
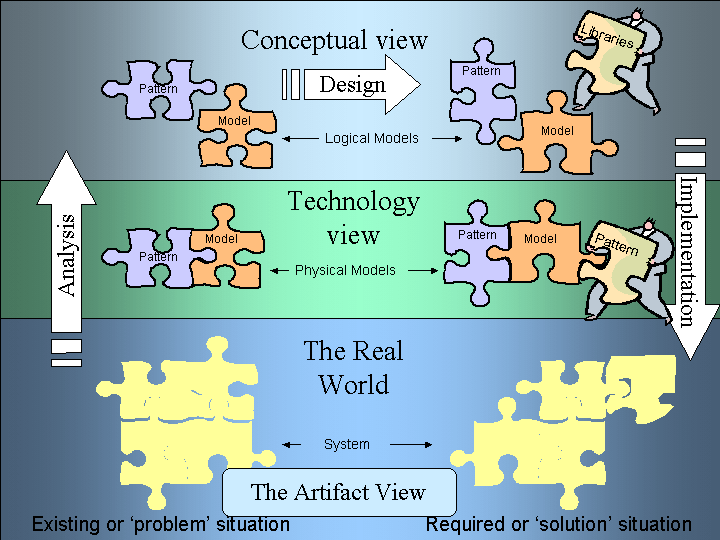
We start with a system operating in the real world.
Our analysis reveals a physical model comprising of both models and patterns (repeating bits of models). These are tightly coupled in that every pattern is used by at least one model. For example, the physical model for student details structure may contain many repeating patterns, such as alternate addresses, student class transcripts, etc.
When we develop our logical model and examine the concepts of the models, we can separate the distinct parts of the model from the patterns that recur. We can move the structures of student transcript and address apart from the student details. This leads us to ask the question "Where can I use these patterns again?"
This is now designing (or re-designing) our models to better suit their requirements. One way we can look for improvements is in re-using patterns, the other is to bring in re-usable patterns from other places. These pattern libraries may be other systems, published standards or self-developed libraries. By doing this at the conceptual view, we are not limiting ourselves to re-use libraries that happen to share the same technology -- we can use logical models from a range of sources.
When we come to build the physical model (the working drawings), we now how two methods for re-using patterns. Not only can we build the logical patterns we saw before, but we may also be able to adopt physical model patterns as well. For example, if we were working in an XML environment, we can chose to adopt data type definitions and stylesheets from other XML libraries.
The final outcome of this is the new system. Now we have a system that capitalizes on re-used patterns and thus is further down the path to interoperability.
We mentioned earlier that Document Engineering perceives of electronic business as documents and processes. Let us now focus in on the document view of this landscape.
A document can be seen as a complex series of relationships between three views of an object: content, structure and presentation. Content is the pieces of information in the document, structure is the arrangement of the content and presentation is the cosmetic display of both structure and content. For example a SIMS Application Form requires content, arranges this in sensible groupings (personal details, course details, etc.) and is presented using appropriate fonts, indentations, shading, etc. There are sophisticated interconnections between some of the parts, which requires document engineering skill for an analyst to identify.
Figure 4. The Document View
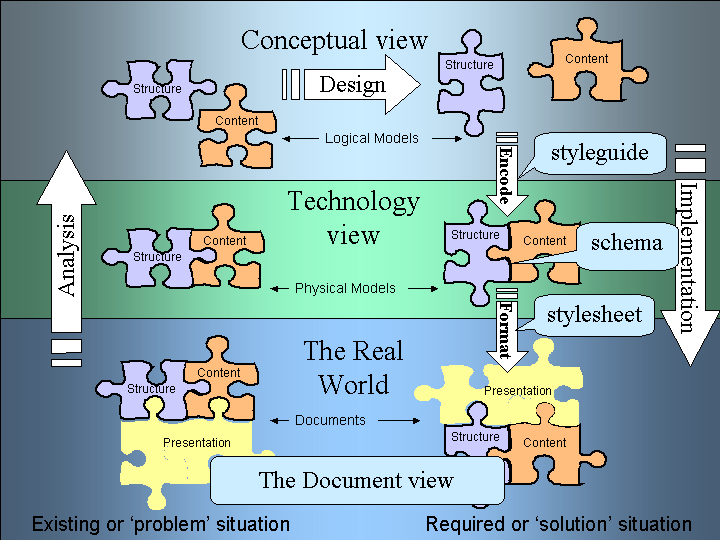
The first task is to identify and remove the document parts that provide only presentation features (see Figure 4.). These are specific to each implementation and should not be involved in our analysis. Our physical model comprises the actual content and the structures around it. So, in our SIMS Application Form, it is the data items and their groupings that we are concerned with. We won't worry about font sizes until we come to implement our re-designed document.
At the conceptual level, we can separate the content from the structure. By this we mean we can model and design each separately. This means we can model that our SIMS Application Form document may have a set of structures dealing with academic content and another with personal content and another with financial content. The modeling of the content and the structures should be separate to allow us to identify patterns of content across structures and patterns of structures across content.
When we come to bring our revised structures and content together, we are assembling a logical view of the new document. We take the content items and the re-usable ones and assemble them into the new structures. For example, we decide what content should be in our SIMS Application Form and in what structures. The Application Form itself being the top-level structure.
An important thing to remember here is that we are still dealing with logical models; this is a conceptual view of our document. Therefore, we may chose to take some of our patterns for re-use from existing models, such as industry guidelines, existing applications, common industry practice or international standards. We are not yet limited by needing common technology platforms for these libraries. We can take a logical model that best suits our document requirements into the physical implementation model.
When we come to build data definitions or XML schemas for these documents, we are transforming our logical model into a physical one. At this point we may need to customize our model to suit the technology. For example, if we are building XML schemas, we may have assigned names to content that are inappropriate for XML tag names. If we are designing database schemas, then maybe our database doesn't support the data types of our model. There will inevitably be a difference between the conceptual, logical model and the pragmatic, physical model. Therefore, it is important we recognise what these compromises were and how they have affected our models. This is the realm of the programmer's styleguide.
At this stage, we may also bring in re-use libraries of structures from other places. For example, the W3C Schema data types for XML Schemas.
Having constructed our schemas we transform these into real world documents using some form of transformation. Transformation puts back the presentation parts we removed earlier. We have already seen how XML handles transformation like this, using XSL stylesheets.
The last part of our story is to examine the 'yang' of our Document Engineering approach -- the business processes that generate and consume the documents.
To show the role of business process, we define our real world e-business system as a complex interrelationship of document and processes. Once again, these are symbiotic; each has evolved to suit the needs of the other.
When we build our models at the technology view we try to identify specific processes and their related documents. For example, we might identify the SIMS Application process and the documents associated with it. This process will connected with other processes, but we tackle the modeling of processes from a top-down approach. The tasks identified as requirements of our system should guide the specific choice of process or levels of processes. This step is shown in Figure 5.
Figure 5. The Business Process View
The modeling of documents is part of the Document View we just discussed. Our process models may reference significant document content, for example when a data element is needed as a key to identify correlated documents or to trigger certain activities. But, on the whole, process models are not strongly concerned with the content or structure of documents, their primary concern is that these documents exist. Typically, this is expressed in the form of messages exchanged between processes.
The design of new processes follows the same approach as with documents. We look for re-use, remove redundancy or duplication of effort, combine and establish re-usable processes where possible.
This new processes needs to be mapped back to the relevant documents as part of the document and process assembly. In fact, documents can be seen as another type of re-use library available to the process.
When a process adopts a set of documents it does so within its own specific requirement, we refer to this as its 'context'. For example, the context in which a business process for Reactivate Student Enrolment will use an Application Form will vary from that used by the business process, New Student Enrolment. It may be that parts of the document become redundant (e.g. reason for deactivation) and others (e.g. Student ID) become essential.
Context is the key driver when defining the relationship between business processes and documents in the physical model.
Ultimately, the business processes we have designed have to be implemented alongside the entire suite of other processes that operate in the real world. If we have done a good job, then these processes will interoperate using our properly engineered documents.
We have presented a roadmap upon which the various aspects of Document Engineering can be described.
The world of e-business was portayed as a complex interaction of business processes and the documents they generate and consume. Through various stages of analytical de-construction and designed re-construction incorporating re-usable objects, we saw how Document Engineering can assist in creating e-business systems capable of interoperating with each other.
Copyright © 2002 Tim McGrath and Robert J. Glushko. All Rights Reserved.