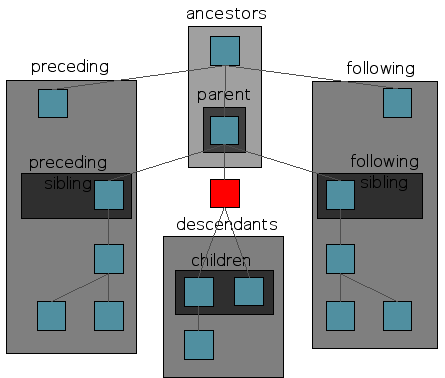
Figure 1. Relationships from the red node.
Basics of XPath
R. Alexander Milowski
milowski at sims.berkeley.edu
#1
XPath
XPath is a syntax for "addressing" into a document.
They are "path expressions".
It allows you to expression things like:
The "para" child element of the "contents" element.
The next sibling of the "item" element.
The "item" element where the attribute "overbid" has value "true".
It is its own "mini standard" used by many specifications.
#2
Like Directory Paths
XPath expressions have a directory-path-like syntax.
A single "/" (forward slash) represents the Document info item--also know as the root.
Subsequent named "steps" in the path represent children:
/doc/title
selects the 'title' child element of the document element 'doc'.
But they don't have to be "rooted":
contents/para
selects the 'para' child element of the 'content' element.
#3
Node Set Results
The result of evaluating an XPath expression is a Node Set.
A node is just another term for "info item".
For example, given the content:
<contents> <para>One</para> <para>Two</para> <para>Three</para> </contents>
the expression:
/content/para
would return three 'para' elements as a set.
#4
Selecting Attributes
You can also select attributes by adding the step: @name
For example, given the content:
<contents> <para><a href="one.html">One</a></para> <para><a href="two.html">Two</a></para> <para><a href="three.html">Three</a></para> </contents>
the expression:
/content/para/a/@href
would return the attribute 'href' of each of the three paragraphs as set.
#5
Names and Namespaces
Any step expression can use a QName: h:body
The prefix binding is defined external to the expression (e.g. application specific).
Matching is based on the local name and namespace name and not the prefix.
We could add namespaces to the previous examples:
/s:contents/d:para /s:contents/d:para/h:a/@href
The application would have to define the prefixes 's', 'd', and 'h'.
#6
No Prefix = No Namespace
A name test without a prefix only matches something without a namespace.
For example:
m:section/title
matches
<m:section xmlns:m='urn:...'> <title>No Namespace</title> </m:section>
but not
<m:section xmlns:m='urn:...' xmlns='urn:something-else...'> <title>I've got a namespace</title> </m:section>
Remember, name matching is based on local name and namespace name alone!!!
#7
Wildcards
The '*' (asterisk) can be used to wildcard names.
Elements: All the elements contained in a 'content' element.
contents/*
Elements: All the attributes of 'para'.
para/@*
Namespaces can also be used:
s:contents/d:* d:para/@h:*
#8
Context Node
Evaluation is always with respect to a context node.
You can address the context node as '.' (period):
For example, the attributes of the context node:
./@*
The context node is implicit.
For example, these are equivalent:
contents/para ./contents/para
The context node does not have to be an element.
#9
Parent and Ancestors
From the context node you can access your parent and ancestors.
Just like directories, '..' represents the parent.
You can go back many levels:
../../section
This selects the 'section' element that is the context node's parent's parent
#10
Conditional Matching
Predicates on the step allow conditions to be specified.
They follow the step and are wrapped in square brackets ('[' and ']').
For example:
para[@id='mine']
selects 'para' elements where the 'id' attribute has value 'mine'.
There is a whole wealth of operators (including boolean logic) that can be used.
You can also have sub-expressions:
contents[para/@id='mine']
This selects a 'contents' element that has a child 'para' with an attribute 'id' of value 'mine'.
#11
Skipping Levels
You can match elements that aren't direct children with the "//" (double forward slash).
This looks through the descendants of the "current context".
For example:
/section//cite
will match all 'cite' elements that are descendants of 'section'. But:
//cite
will match all 'cite' elements in the document.
#12
Special Functions
There are some special functions that can be used as steps.
| Function | Result |
|---|---|
node() |
Matches any kind of node. |
text() |
Matches text. |
processing-instruction() |
Matches a processing-instruction. |
comment() |
Matches a comment. |
For example:
para/node()
matches all the children of a 'para' element including comments, text, and processing instructions.
#13
The Real Story
This is all just an abbreviated syntax.
There is a lot more...
We'll start by explaining the "axes" of a document.
#14
Trees and XML
For the computer scientists:
Formally, a tree is a connected, acyclic, undirected graph.
It would be nice if XML was a rooted positional n-ary tree.
XML isn't that simple.
But the parent-child relationships in the infoset do form a tree.
Attributes and namespaces mess this up a bit.
#15
Relationships in a Tree
Figure 1. Relationships from the red node.
#16
Additional XML Relationships
Attributes:
Each element can have attributes.
Attribute info items aren't children.
Namespaces:
Each element can have in-scope namespaces.
Namespace info items aren't children.
#17
Axes are Directions on Relationships
|
|
#18
Axis Syntax
Steps can be preceded by an axis name and a double colon:
contents/child::para para/preceding-sibling::* ancestor::section/title
If that relationship doesn't exist, you get an empty node set.
#19
Axis Specifics
Each axis has:
A direction of forward or reverse.
A principal node type: one of attribute, namespace, or element
The direction refers to the order in which items will be traversed.
#20
Principal Node Type
The principal node type refers to what a name matches:
On the 'child' axis, a name matches an element.
On the 'attribute' axis, a name matches an attribute.
Principal node type "special cases" the extra relationships:
Only the attribute axis has type 'attribute'.
Only the namespace axis has type 'namespace'.
Everything else has type 'element'.
#21
Axis Direction
Reverse Axes:
ancestor
ancestor-or-self
preceding
preceding-or-self
Everything else has a forward direction.
#22
Axis Direction - Example
For example, give the following
<doc> <a/><b/><c/> <target/> <d/><e/><f/> </doc>
These expressions evaluate:
target/preceding-sibling::* → elements 'c' b' 'a'.
target/following-sibling::* → elements 'd' 'e' 'f'.
#23
Abbreviated Syntax Equivalences
| Abbreviation | Equivalence |
|---|---|
../name |
parent::name |
name |
child::name |
//name |
descendant::name |
. |
self::node() |
* |
child::* |
@* |
attribute::* |
@name |
attribute::name |
#24
What use is this?
XPath is used extensively in XSLT to process and transform XML documents:
<xsl:transform version='1.0'
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<head><xsl:apply-templates select="doc/title"/></head>
<body>
<xsl:apply-templates select="doc/contents"/>
</body>
</html>
</xsl:template>
</xsl:transform>
XML Schema and other standards use this for similar matching needs.
Many programming APIs & commercial products provide XPath for traversing and manipulating XML.