-
This is the simplest need from an application perspective:
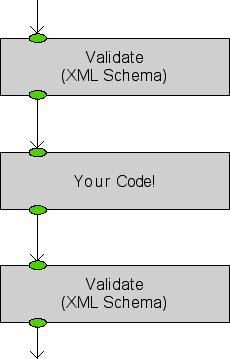
Figure 1. Figure
-
Here we just wrap custom code with a schema validate on the input and output.
Processing Models and XML Pipelines
R. Alexander Milowski
milowski at sims.berkeley.edu
#1
Processing is Always a Multi-step Procedure
Processing XML is always multi-step.
For example:
Parse XML
Validate XML w/ Schema
Use XML
Throw in a transformation or two...
...and you get a mess.
#2
Parsing & Processing
You at least parse the document, process it, and serialize some result: that's three steps.
Parsing and serialization are somewhat implicit in most systems.
A better example is schema validation:
Schema validation adds information to the infoset (e.g. type names, validity flags, etc.).
Schema processing before an application component would give an application component more information.
Based on whether that document is valid or not, you might do different things.
There are lots of component specifications:
XML Schema
XSLT, XPath, XML Query
XPointer, XLink
XML Base, XInclude
SOAP
etc.
#3
Example: Aggregation
Say you have references (e.g. xincludes) in one document that you'd like to replace with their contents.
You'd also like to style the result to XHTML for viewing in a browser.
You've got two seperable steps:
Transform the input document replacing references with the referenced--mayve via an XInclude processor.
Transform the result of (1) into XHTML via XSLT.
#4
Pipeline Motif
We can think of these chains as pipelines in which components pass output to input.
This is analogous to Unix pipes where one program's input is the output of the previous.
The difference is here we are passing XML between the components--ideally as infosets and not XML syntax streams.
Definition 1:
An XML Pipeline is a sequence of components each of which consumes a "primary" infoset and produces a "primary" infoset.
#5
Example: Aggregation Implemented via JAXP
We can just write a JSP page that does this via JAXP
...or we could have written a java program/library just as well.
The jsp page's main code (using the last lecture's code):
// Setup the transformations
Transforme aggregate = getTransform("aggregate.xsl");
Transforme style = getTransform("style.xsl");
// Create a DOMResult to hold the between XML document
DOMResult between = new DOMResult();
// Transform the input
aggregate.transform(new StreamSource(request.getQueryString()),between);
// Transform the output of step 1
style.transform(new DOMSource(between.getNode()),new StreamResult(out));
#6
Application Needs
What is needed is a specification of the processing model.
Something that applications can use to efficiently organize these steps.
Something that vendors can use to design infrastructure for application builders.
Many people call these "pipelines".
#7
Pipelines
This paper is really the first instance of this idea:
D. McKelvie, C. Brew, and H. Thompson. Using SGML as a Basis for Data-Intensive NLP. In Proceedings of the fifth Conference on Applied Natural Language Processing (ANLP-97) 1997
Here's that article: anlp97.pdf
The pipes are "fat" because they pass XML between components.
Definition: A pipeline is a chaining of XML-in-XML-out components.
Note: The chaining doesn't have to be a simple "line" components strung output-to-input.
#8
Pipeline Example 1
This is the simplest need from an application perspective:
Figure 1. Figure
Here we just wrap custom code with a schema validate on the input and output.
#9
Pipeline Example 2
Here we chain together "simple" transformations:
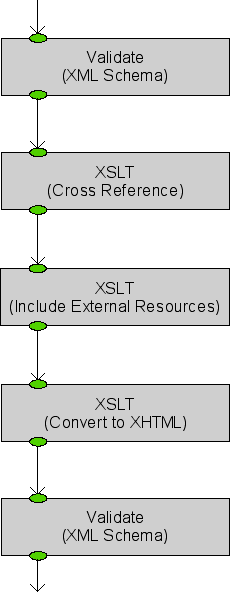
Figure 2. Figure
#10
A "Real" Pipeline
This converts my "mathdoc" documents into latex:

Figure 3. Figure
I need multi-step pipelines to deal with escaping of characters and unicode.
I need two outputs since my citations need to be in a separate input file for latex.
#11
Possible Pipeline Components
XInclude, XML Base
XML Schema, Relax NG, Schematron
XSLT, XPath Filtering, XML Query
"micro operations": Element/attribute elimination, Element/attribute value setting, etc.
#12
Data Flow & Pipelines
In a pipeline, the data controls the flow.
To make something happen, you have to add/modify/remove XML elements.
That is, each "step" in the pipeline produces content that instructs the next step what to do.
#13
Pipelining Languages/Technologies
Sun's XML Pipeline Note at the W3C - language specification
Norm Walsh's sxpipe project at Java.net - open source - language and implementation
My smallx project at Java.net - open source - language and implementation
Apache's Cocoon - open source - chaining of SAX filters in the sitemap.
Markup Technology - commercial - language and implentation - also implements (1).
Orbeon - open source/commercial - language and implentation embedded in product.
#14
Smallx
smallx is a project on java.net (Sun's open source foundry).
It is a set of API's and implementations that support:
Processing of infosets as event streams or whole trees.
Full XSLT and XPath 1.0 on the native infoset API.
A streaming XPath subset.
XML Pipelines
It is open source available under a BSD license.
#15
Smallx History
This is software I've been developing on-and-off for the past four years.
My main motivation was to be able to efficiently process large XML documents (100MB-1GB) as streams.
I also wanted to be able to manipulate documents without whole in-memory trees.
Only recently did it come out from under IPR restrictions.
#16
Smallx Pipelines
Smallx pipelines are chains of components (e.g. XSLT, schema, code, etc.)
All components communicate by "streams" of infoset events.
Components can also have hierarchy so they can use children components to accomplish a larger task.
Pipelines are specified via an XML document.
Example: "Aggregate" and "Style"
<p:pipe xmlns:p="urn:publicid:IDN+smallx.com:pipeline:1.0" name="example"> <p:xslt src="aggregate.xsl"/> <p:xslt src="style.xsl"/> </p:pipe>
#17
Smallx Pipelines - Components
Smallx pipelines contain a growing set of components:
Add/Delete/Rename - element-level manipulation
Document - static content inclusion
Escape/Parse - escaping XML and parsing escaped XML.
File - file manipulation, directory listings, loading/writing XML from/to files.
Routing - subsequence routing based on xpath expressions
Subtree - scoping pipelines to specific subtrees.
URL - URL resource manipulation (post/get)
Trap - Error handling
XSLT - Applying XSLT to a stream.
#18
Smallx - Large Document Example
This pipeline processes a large data file that is an XML document. Each 'training-scenario' element can be processed by XSLT but the whole document is too big to load into one in-memory tree. The output is a text data file that can be read by statistical software.
<p:pipe xmlns:p="urn:publicid:IDN+smallx.com:pipeline:1.0" name="scenario2text"> <!-- Limits the XSLT to the 'training-scenario' element --> <p:subtree-view select="training-scenario"> <!-- Converts the scenario data to a text file for R --> <p:xslt src="scenario2text-xt.xsl"/> </p:subtree-view> </p:pipe>
#19
Smallx - Aggregation Example
This pipeline processes a large data file that is an XML document. Each 'training-scenario' element can be processed by XSLT but the whole document is too big to load into one in-memory tree. The output is a text data file that can be read by statistical software.
<p:pipe xmlns:p="urn:publicid:IDN+smallx.com:pipeline:1.0" name="scenario2text"
xmlns:c="urn:publicid:IDN+smallx.com:component-language:1.0"
>
<!-- add the aggregation specification to the input -->
<p:template>
<result>
<c:file href="header.xml"/>
<xsl:copy-of select="."/>
<c:file href="trailer.xml"/>
</result>
</p:template>
<!-- Aggregate by running through the file component -->
<p:file/>
</p:pipe>
#20
sxpipe
sxpipe is a pipeilne language and implementation written by Norm Walsh.
It passes whole document trees between components.
Inputs to each component are either the previous stage element or specified by an attribute.
Example:
<pipeline xmlns="http://sxpipe.dev.java.net/xmlns/sxpipe/"> <stage process="XInclude"/> <stage process="Validate" schema="book.xsd"/> <stage process="Transform" stylesheet="book2html.xsl"/> <stage process="Write"/> </pipeline>
#21
sxpipe Components
The following components are supported:
identity
validate
read
write
xinclude
transform
Its got a Java API and so you can add your own as well.
#22
Cocoon Pipelines
Cocoon pipelines are chains of SAX handlers.
This means each component is intimately intertwined with the next!
But you can do alot of things very efficiently this way:
The implementation is streaming.
Low memory consumption.
Faster response times.
#23
Event Application Example
The basic pipeline architecture:

Figure 4. Figure
#24
Event Application Example - Syntax
Here's the configuration in the sitemap:
<map:match pattern="*.post">
<!-- generate XML from the form data -->
<map:generate type="serverpages" src="form-result.xsp"/>
<!-- Process the form into a app-specific format -->
<map:transform src="{1}.post2xml.xsl"/>
<!-- Handle any web service specifics -->
<map:transform src="{1}.pre-service.xsl"/>
<!-- Talk to the web service. This is a custom CDE component that was
built to allow Cocoon to serialize the content in the pipeline to
a web service connection and the parse the response. -->
<map:transform type="webservice">
<map:parameter name="url" value="http://localhost:8080/webservice/event.service"/>
</map:transform>
<!-- Here we have the response from the web service in the pipeline. -->
<!-- Decode the response -->
<map:transform src="{1}.post-service.xsl"/>
<!-- Format the result for the browser -->
<map:transform src="{1}.final.xsl"/>
<!-- Serialize to the waiting browser connection.-->
<map:serialize type="xhtml"/>
</map:match>
#25
Sun Pipeline Language
Sun authored a specification language for pipelines.
Its an XML document that describes the flow.
You can see the note at: http://www.w3.org/TR/xml-pipeline/
More information is available at Sun's website.
#26
An Example:
Here's an example from their web page:
<pipeline xmlns="http://www.w3.org/2002/02/xml-pipeline"
xml:base="http://example.org/">
<param name="target" select="'result'"/>
<processdef name="xinclude.p" definition="org.example.xml.Xinclude"/>
<processdef name="validate.p" definition="org.example.xml.XmlSchema"/>
<processdef name="transform.p" definition="org.example.xml.XSLT"/>
<process id="p1" type="xinclude.p">
<input name="document" label="myfile.xml"/>
<output name="result" label="xresult"/>
</process>
<process id="p2" type="validate.p">
<input name="document" label="xresult"/>
<input name="schema" label="someschema.xsd"/>
<output name="result" label="valid"/>
<error name="invalid" label="#invalidDocument"/>
</process>
<process id="p3" type="transform.p">
<input name="stylesheet" label="mystyle.xsl"/>
<input name="document" label="valid"/>
<output name="result" label="result"/>
<param name="chunk">0</param>
</process>
<document name="invalidDocument">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Failure!</title>
</head>
<body>
<h1>Your job failed because the document is invalid.</h1>
</body>
</html>
</document>
</pipeline>
#27
Processors
A processor is declared by the pipeline.
Syntax:
<p:processdef name = xs:ID definition = xs:string />
The 'definition' attribute value is implementation defined.
You use this to declared your XSLT, XML schema, etc. implementations.
#28
Steps
Steps are represented by 'process' elements.
Syntax:
<p:process id = xs:ID type = xs:IDREF ignore-errors = xs:boolean > <!-- Content: ( p:input | p:output | p:error | p:param | foreign-content )* --> </p:process>
Each process can specify inputs and outputs.
#29
Inputs and Outputs
Inputs are matched to outputs by labels.
If inputs aren't files, then they should be the output of some process.
This is like make or ant.
#30
Latex Example
My latex pipeline:
<pipeline xmlns="http://www.w3.org/2002/02/xml-pipeline"
xml:base="http://example.org/">
<param name="target" select="'result'"/>
<processdef name="filter.p" definition="org.mathdoc.tools.FilterUnicode"/>
<processdef name="validate.p" definition="org.example.xml.XmlSchema"/>
<processdef name="transform.p" definition="org.example.xml.XSLT"/>
<process id="m1" type="validate.p">
<input name="document" label="mydoc.xml"/>
<input name="schema" label="mathpaper.xsd"/>
<output name="result" label="valid"/>
<error name="invalid" label="#invalidDocument"/>
</process>
<process id="m2" type="transform.p">
<input name="stylesheet" label="paper2tex.xsl"/>
<input name="document" label="valid"/>
<output name="result" label="texresult"/>
<param name="chunk">0</param>
</process>
<process id="m3" type="filter.p">
<input name="document" label="texresult"/>
<output name="result" label="filtered"/>
</process>
<process id="m4" type="transform.p">
<input name="stylesheet" label="finalsyntax.xsl"/>
<input name="document" label="filtered"/>
<output name="result" label="mydoc.tex"/>
</process>
<process id="b1" type="transform.p">
<input name="stylesheet" label="paper2bib.xsl"/>
<input name="document" label="valid"/>
<output name="result" label="bib-texresult"/>
<param name="chunk">0</param>
</process>
<process id="b2" type="filter.p">
<input name="document" label="bib-texresult"/>
<output name="result" label="mydoc.bib"/>
</process>
<document name="invalidDocument">
<error>
Your document is not valid!
</error>
</document>
</pipeline>
#31
Pipelines as Web Services
One of the best uses of pipelines is to implement web services.
It is a natural fit because web services are always multi-step as you want to at least do:
Validate the input.
Process the input.
I've built an integration of smallx pipelines as both servlets and filters.
#32
Example Web Service - BART Schedule
We want to send a simple request of start and end station with a departing time to get a train schedule:
We'll receive an XML document with the necessary information.
We'll need to post that information to the bart website.
Process the XHTML that comes back to get the schedule results.
Return that schedule as XML.
#33
BART Schedule Input
The request:
<bart-schedule> <from>BRK</from> <to>EMBAR</to> <departing><month>2</month><day>17</day><time>5:00 PM</time></departing> </bart-schedule>
#34
BART Schedule Output
The request:
<routes> <from>BRK</from> <to>EMBAR</to> <departing><month>2</month><day>17</day><time>5:00 PM</time></departing> <route-option> <train> <depart>Downtown Berkeley at 4:55p</depart> <board>Millbrae train</board> <arrive>Embarcadero at 5:17p</arrive> </train> </route-option> <route-option> <train> <depart>Downtown Berkeley at 5:02p</depart> <board>Fremont train</board> <arrive>MacArthur at 5:08p</arrive> </train> <train> <depart>MacArthur at 5:08p</depart> <board>Millbrae train</board> <arrive>Embarcadero at 5:24p</arrive> </train> </route-option> </routes>
#35
BART Schedule - Procedure
We need to turn the input XML into a HTTP request while keeping a copy of the to/from/departing information.
Make the request to the resource over HTTP.
The result isn't quite valid XHTML--darn! So, we'll use tagsoup (a SAX HTML parser) to parse it as HTML to feed it as XML.
www.bart.gov returns complicated stuff with lots of tables. We need to locate the right table and dump the rest.
The remaining table is the train schedules--so convert that to the right XML elements.
#36
BART Schedule as a Smallx Pipeline
<p:pipe xmlns:p="urn:publicid:IDN+smallx.com:pipeline:1.0" name="bart-schedule"
xmlns:c="urn:publicid:IDN+smallx.com:component-language:1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:h="http://www.w3.org/1999/xhtml"
>
<!-- Scope the service to the bart-schedule elements -->
<p:subtree select="bart-schedule">
<!-- Translate the request to a 'routes' element and add the c:url-get input
for the url component -->
<p:template>
<xsl:for-each select="bart-schedule">
<routes>
<xsl:copy-of select="node()"/>
<c:url-get href="http://www.bart.gov/index.asp?origin={from}&destination={to}&time_mode=departs&depart_month={departing/month}&depart_date={departing/day}&depart_time={substring-before(departing/time,' ')}%20{substring-after(departing/time,' ')}&cookiesTested=1"
parse-as-html="true"/>
</routes>
</xsl:for-each>
</p:template>
<!-- Get the schedule -->
<p:url/>
<!-- delete unnecessary elements -->
<p:subtree select='h:script|h:meta|h:head'>
<p:delete/>
</p:subtree>
<!-- Find the contents table and drop the rest -->
<p:subtree select="h:table">
<p:template>
<xsl:copy-of select="h:table/h:tbody/h:tr/h:td[h:a/@name='content']/h:div[@id='bodytext']/h:table[contains(h:tr[1]/h:td[1],'Your Schedule')]"/>
</p:template>
</p:subtree>
<!-- Find the schedule tables and drop the rest -->
<p:subtree select="h:table">
<p:xslt>
<xsl:transform version="1.0">
<xsl:template match="/">
<search-results>
<xsl:apply-templates select="h:table/h:tr/h:td/h:table/h:tr/h:td/h:table"/>
</search-results>
</xsl:template>
<xsl:template match="h:table|h:tr|h:td|h:a">
<xsl:copy>
<xsl:apply-templates select="@href|node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="h:br"><xsl:text> </xsl:text></xsl:template>
<xsl:template match="@*"><xsl:copy/></xsl:template>
</xsl:transform>
</p:xslt>
<!-- Translate the schedule tables into the 'route-option' element -->
<p:xslt>
<xsl:transform version="1.0">
<xsl:template match="h:table[not(preceding-sibling::*)]"/>
<xsl:template match="h:table" xml:space='preserve'>
<route-option>
<xsl:apply-templates select="h:tr"/>
</route-option>
</xsl:template>
<xsl:template match="h:tr[not(preceding-sibling::*)]"/>
<xsl:template match="h:tr" xml:space='preserve'>
<train>
<xsl:apply-templates select="h:td"/>
</train>
</xsl:template>
<xsl:template match="h:td[1]">
<depart><xsl:value-of select="normalize-space(.)"/></depart>
<xsl:text>
</xsl:text>
</xsl:template>
<xsl:template match="h:td[3]">
<board><xsl:value-of select="normalize-space(.)"/></board>
<xsl:text>
</xsl:text>
</xsl:template>
<xsl:template match="h:td[4]">
<arrive><xsl:value-of select="normalize-space(.)"/></arrive>
<xsl:text>
</xsl:text>
</xsl:template>
<xsl:template match="h:td"/>
</xsl:transform>
</p:xslt>
</p:subtree>
<!-- drop extras that remain -->
<p:subtree select='h:br'>
<p:delete/>
</p:subtree>
<!-- Unwrap the route-options from the XHTML -->
<p:unwrap select='h:html'/>
<p:unwrap select='h:body'/>
</p:subtree>
</p:pipe>