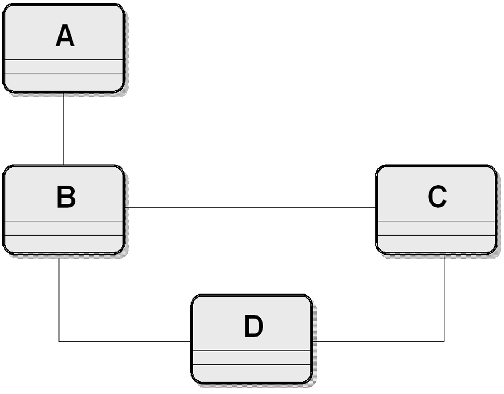
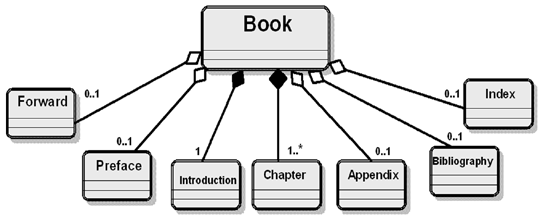
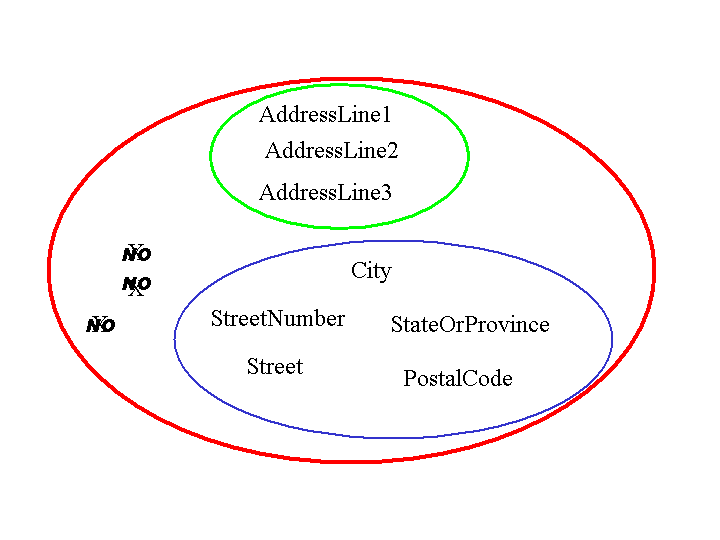
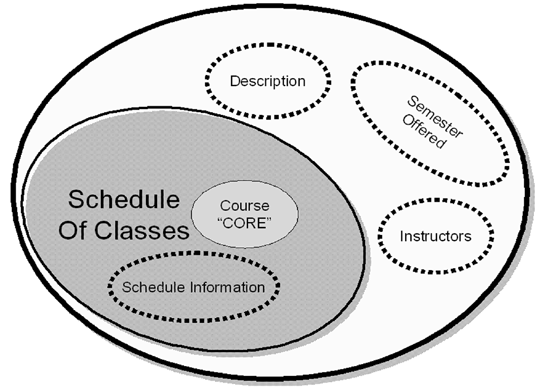
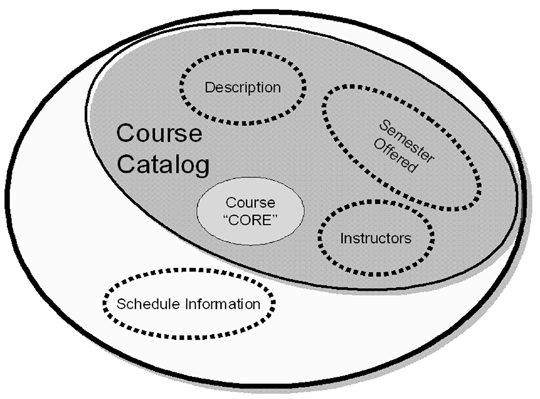
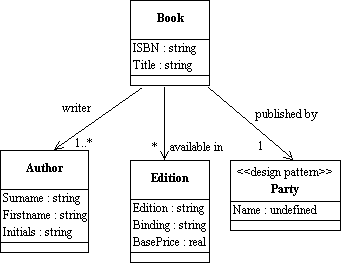
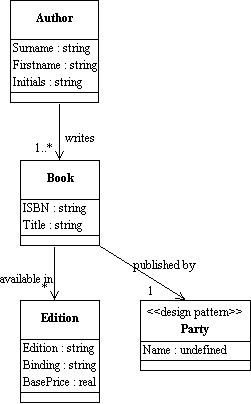
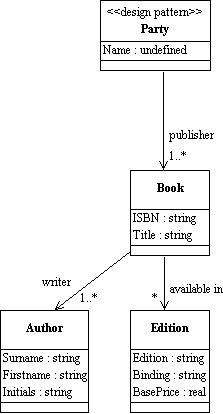
Document model assembly is the process of creating a model of a document type – hierarchical and nested – by drawing on the "pool" or library
of content and structural components
Assembly involves designing (or selecting a pattern for) the top level structure as an entry point
and then navigating through the relationships in the conceptual model collecting the components in
the order that best satisfies your requirements
Assembly order can differ whenever there is a bi-directional relationship between components – whenever two components are functionally independent, an assembly order chooses one of the relationships to enforce an interpretation on the assembled document
The direction of following the relationship determines which of the structural roles is being used
We end up with a specific context-sensitive view of the model
This is the logical basis of the document schema – all we have left to do is to encode it as an XML schema