PIPs - Raw Usage
Copyright 2006 Robert J. Glushko
Review of Assignment 7 -- Business Process Analysis
Introducing Document Analysis
Presentation, Structure, and Content
Balancing "in vitro" vs "in vivo"
Comparing models -- transactions & collaborations; transaction patterns; PIPs
Comparing methodologies
Comparing tools
Comparing diagrams
What was the process by which you developed your model?
Do worksheets -> diagrams, or diagrams -> worksheets?
When did you start thinking about the PIPs and transaction patterns?
Activity 1 to "Define the Context" was meant to be a less rigorous substitute for creating a "Business Process Area Worksheet" like Figure 9-4b.
Almost all of you stuck with my 6 actors but some proposed "smog test" role
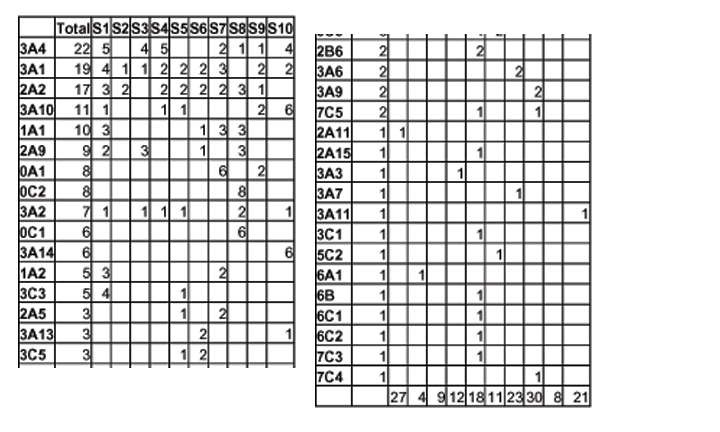
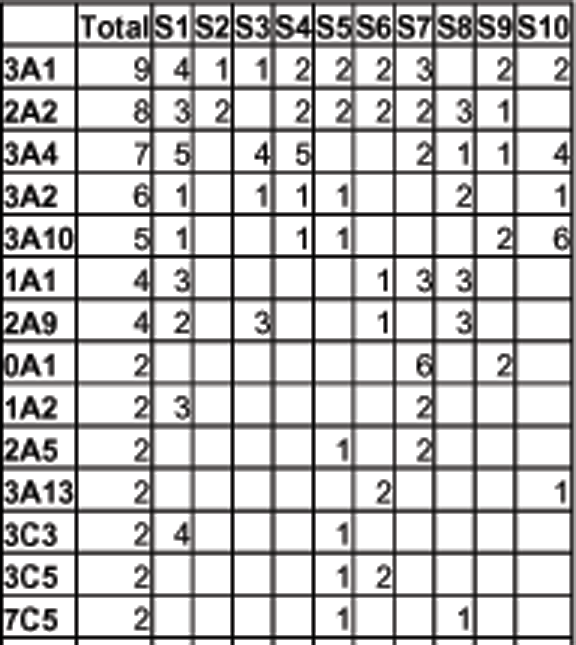
# of transactions ranged from 6 to 25, with mean of 11.4
Many of you didn't define any collaborations. But for those who did, # collaborations ranged from 2 to 8, with mean of 4.3
# of transactions / collaboration ranged from 1.5 to 8, with mean of 4.2
Information gathering/ research (5)
Assess car general value (1), Assess car specific value (1), Evaluate car (1), Select car (1)
Negotiation (4), Purchase (2)
Insurance (3), Driver's License (1), Smog certificate (1), Transfer ownership (1)
Registration (3)
A transaction worksheet defines a "metamodel" -- the types of information needed to define any kind of transaction
Useful in developing and understanding the model?
If you were implementing someone else's model?
See Business Process Analysis Worksheets and Guidelines v1.0 (http://www.ebxml.org/specs/bpWS.pdf)
You had precise requirements for what to depict in your model, but not how to depict it
How well do each of these diagrams satisfy the representational and communicative goals?
How does the model influence the diagram?
Does the choice of diagram influence the model?
Did you use the cluster/segment/PIP hierarchy?
Are PIPs helpful in understanding the model?
Or a tedious documentation chore for you?
But if you were implementing someone else's model?
Why are your models so different?
Would they be as different on a subsequent assignment?
What should we learn from this?
When we analyze information sources: interviews, documents, sets of data whatever - our goal is to identify and describe the "significant things" or the "information components" and their characteristics or attributes
If you conduct an interview your source will naturally talk about information components as abstract pieces of information
But when you analyze documents the information components aren't as immediately apparent because they are contained in structures and rendered in some presentation
So we have to remove the presentational information and dis-assemble the structural information to find the content information that is our highest priority
As we take away presentation and structure, we are abstracting away or generalizing from a physical implementation and creating our first conceptual or logical model of the information components
Components – the units of content
Any piece of information that has a unique label or identifier is a candidate component
Any piece of information that is self-contained and comprehensible on its own is a candidate component
A component is a logical unit, with no presentation implied; it may be organized structurally
These definitions are very helpful for finding components in some types of documents but less so in others
It depends on the presence of, and relationships with, the structural and presentational information
We need a vocabulary to classify different kinds of information that we find in documents and sets of data
Content – "what does it mean" information
Structure – "where is it" or "how it is organized or assembled" information
Presentation – "how does it look" or "how is it displayed" information
The "Document Engineering Methodology" can be thought of as:
Distinguishing the three kinds of information in instances or artifacts
Carefully describing their current and desired relationships
Creating conceptual models that describe the content information as it is and as it could be
Using principles of "good design" and patterns to refine the conceptual model
Reassembling or recombining the three kinds of information to achieve the desired relationships in the "instances" or "artifacts," beginning with the conceptual model and then adding structure (creating document schemas) and then adding presentation (with transforms or stylesheets)
Standard approach is facilitation by document analysis experts in face-to-face "workshops" with broad participation
Document creators/users reach consensus with expert help, and then experts systematize it into models and schemas
Document analysis is often carried out as a consulting engagement – with all the complications of defining the project, managing expectations and relationships, and packaging the results for effective use
Document analysis is not quite as variable as process analysis, but it is still essential to validate your own analysis with others, especially the creators/users of the information
Identifying all the potentially relevant documents or information sources is inherently an iterative task
We locate documents, which may refer or link to other documents, and we locate people who work with the documents, who may refer or link to other documents or people
If there are lots of documents of a particular type, we have to be concerned about representiveness and selection biases
Avoid the temptation to assume that job titles and formal organizational structure reflect what people actually do
Likewise, avoid the temptation to assume that the names given to documents fit the people, tasks, and organizations in which we locate them
Regardless of its title, make sure a document is being used before you conclude it is important
Document analysis can be challenging for lots of reasons that have nothing to do with the document per se
"Armchair analysis" - speculating about what a particular document instance is like - is often wrong
Likewise, what the author or editor tells you might be useful - or it might be revisionist history
Your company or your client may be considering a relatively small "tactical" effort like creating Web versions of its product documentation
Or it may be considering a strategic effort to devise a complete "information architecture" and enterprise content management system
In both cases it is essential that you understand the content, structure, and presentation of the information you have because it defines what is possible (and what may not be possible), how much work it will take, and the scale or scope of technology needed to implement your solution
In the tactical project an incomplete or inaccurate document analysis may result in cost and schedule overruns, online documents that are difficult to use and difficult to maintain, customer support or retention problems and operational inefficiencies
In the strategic project an incomplete or inaccurate document analysis may severely hamper the company's ability to carry out its business strategy and may cause it to fail
Human-oriented attributes for visual (or other sensory) differentiation (type font, type size, color, background, indentation, pitch, ...)
Implementation specific (e.g. Web vs print vs auditory)
Good user interface design correlates this with structural or content information, increasingly so as we move away from transactional end of spectrum

Presentation can indicate structural or content information, but it can also conceal it
The "where is it ..." components
Physical piece of a document (e.g. table, section, title, header, footer)
The structural components provide the hierarchical "skeleton" or "scaffold" into which the content components are arranged
The structure also provides a framework for presentation
Structures are often hierarchical - one component can contain others
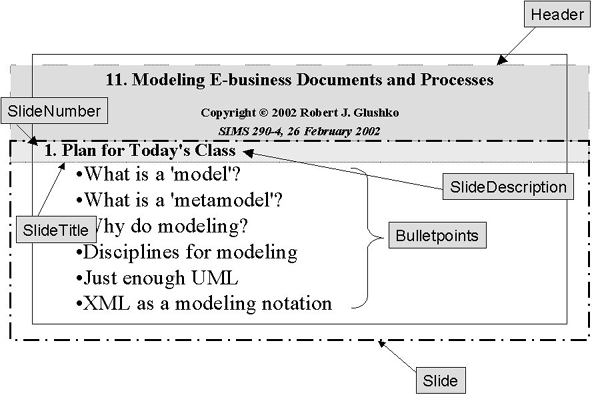
Each lecture has a similar structure but different content
The structure of each slide is also the same
Content components are the "nouns" in our documents or sets of data – things like "topic," "summary," "name," "address," "price"
These are the "what is it..." components
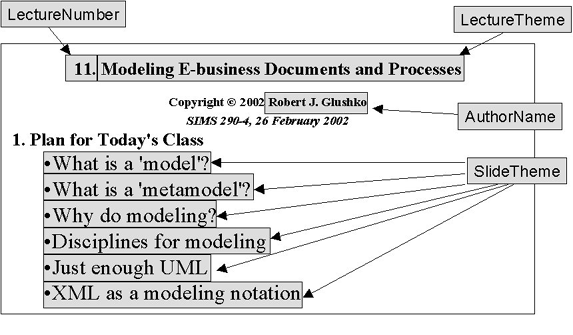
After we've identified the presentation and structural information, what is left is the "meaning" -- the content components
Read DE 12 Again!
"Sylvia: The Syllabus Viewing Application (Overview & The Sylvia Data Model)," Cracraft & de Larios-Heiman (http://groups.sims.berkeley.edu/sylvia/docs/reports/final_report.html)