Home Blueprint
Copyright 2006 Robert J. Glushko
Analysis tour of the Document Type Spectrum
More on content, structure, and presentation analysis
The Harvest Table
Another useful dimension for thinking about content considers the relationship in documents between the text and non-text information that they contain
Text-dominated
Text-framework
Non-text dominated or text-enhanced
The relationship between text and non-text information can vary at all points on the document type spectrum
Narrative document type can be philosophy (all text) or anatomy (lots of non-text)
Transactional document type can be invoice (all text) or RFQ (lots of non-text)
Usually very carefully designed, with regular structure that is exploited in information access and navigation features to enhance usability
Often have rich repertoire of content component types (pictures, maps, charts, formulas, tables)
Mixed content in paragraphs or other text blocks will contain numerous content types that are implicit hypertext
Usually mostly text, created and used by people
Information that is often extremely important to companies and highly-paid professionals because the cost of finding (or not finding) information can be high
Often has high "intrinsic hypertext" character with many explicit and implicit links between content components
Often follow structural conventions and standards with regular numbering and naming schemes
Versioning and configuration requirements can pose problems
Making this type of content computable or executable is a huge R&D area (XML standards like XACML, policy engines and wizards, expert systems)
Many different types
Some are extracted from ERP system or product database
Often contain a mixture of structured and unstructured content
Vocabulary and ontology variation makes it challenging to aggregate or align catalogs
Printed or electronic forms
Data-intensive, designed to capture and present small information components
Inputs and outputs of business processes and often created and consumed by computers
Few and somewhat arbitrary presentational characteristics
Strongly datatyped with field length, range and value, other restrictions
The prescriptiveness of a document type and the homogeneity of instances reflects the number and strength of the constraints about content and structure that you identify in your document analysis
Sometimes the document type is defined with weak constraints and merely descriptive, and thus the instances are heterogeneous in content and structure
But is this heterogeneity an inherent property of the document type, or just the way it has been (implicitly) defined? Could the type be more prescriptive?
"Even within the very limited scope of recent SIMS syllabi, we found a great variety of document types.
Our syllabi ranged from fairly transactional forms, with tables of class titles, readings, and assignments...
...to more narrative documents with long descriptions of topics and discussion questions and a notable lack of specific dates and assignments."
A form may ask you to enter your address this way
Address:
Line 1: _________________
Line 2: _________________
City: ____________ State: ________ ZipCode: _________
But "line 1" and "line 2" are presentation labels that are not useful for any purpose other than printing out an address label
They are not candidate content components
They are masking content components like "number," "street," etc.
"Table of Contents," "Permuted Index," and list of figures, tables, or other types of components can usually be generated or derived from other components and are not components in their own right
Similarly, if "ExtendedPrice" is "Quantity" x "UnitPrice" we might only want the latter two components in our model since collecting that first one separately could lead to data integrity problems
Structural components are often identified by the names attached to pieces of information – think of the outline or table of contents or lists of various kinds
Your analysis goal is to capture the rules for applying numbers or names to content in the hierarchy
Structural levels can suggest distinctions in types of content at different structural levels that aren't real
Many documents, especially those in reference and legal types are very hierarchical. For example, MIL-STD 1472D looks like this:
5.4.2.2. Continuous adjustment rotary controls
5.4.2.2.1 Knobs
5.4.2.2.2.1 Use. Knobs should be used when...
5.4.2.2.1.2 Dimensions, torque, and separation. ...
5.4.2.2.1.3 Knob style. Unless otherwise specified...
5.4.2.2.2 Ganged control knobs
5.4.2.2.2.1 Application. Ganged knob assemblies...
5.4.2.2.2.2 Dimensions and separation. ...
5.4.2.2.2.3 Resistance. ...
5.4.2.2.2.4 Marking. An indexing mark or pointer...
Content components can be related to one another
Derivational relationships
A graduate student is a specialized kind of student
A student is a specialized kind of person
Referential relationships
There is a very large set of possible referential relationships between components
The relationship is sometimes signaled with some presentational or structural component
The type of (or reason for) the relationship is less likely to be explicit
Law review articles contain an incredibly rich set of links for cross-referencing and footnoting (including the use of Latin to signal semantic types and direction). Can you locate:
An "ordinary" footnote from the article text to an associated footnote
A footnote that cites another document
A footnote that cites another part of the same article
A footnote that cites another footnote
A footnote that cites another footnote that contains the citation to another document's footnote?
Why are there so many different kinds of footnotes? Why are they so indirect?
What are the consequences for this variety in transforming printed law review articles into electronic versions?
As we identify candidate content components, we need to record its properties (or attributes or behaviors) that let us understand it and distinguish it from other ones
A practical way to do this for each document or information source being analyzed, create a table or spreadsheet containing the candidate component and the metadata useful in understanding and distinguishing it from other ones
The component won't always have a name so if you must invent one, it is helpful to start a dictionary list of the words that names contain
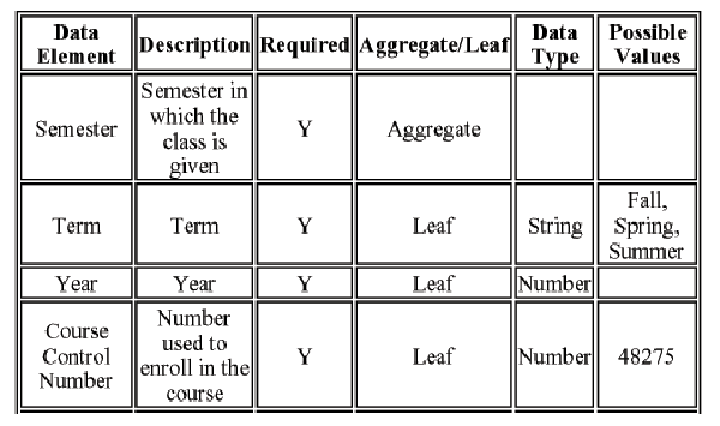
What attributes about each type of content might we record in our analysis?
Names/synonyms/homonyms (what it is called)
Definition (what it "means")
Identifiers
Cardinality/Optionality (occurrence rules)
Restricted values, code sets, defaults
Data Type (text, numbers, date, video)
Relationships/Associations (participation in structures)
Origin (Is this new information, or from some other source? Who maintains it?)
Access (who is allowed to view/change/copy/etc. it)
Permanence (is it static or dynamic? how often does it change?)
Business processes in which it participates
Chapter 13 -- Assembling Document Components