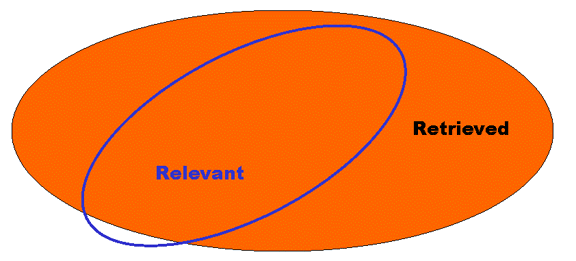
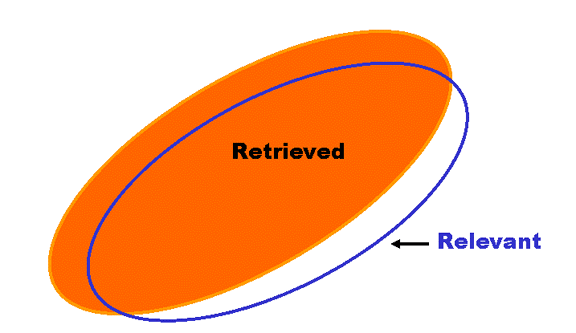
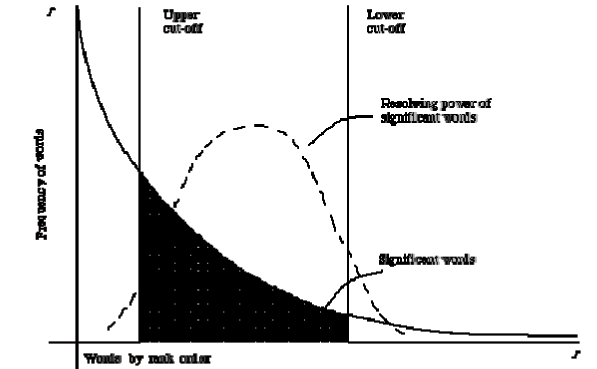
Recall and Precision

Copyright © 2005 Robert J. Glushko


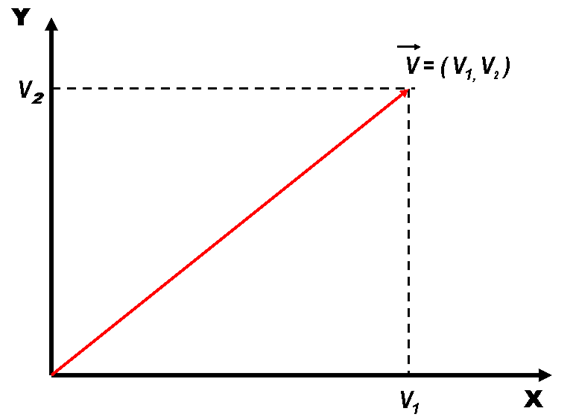

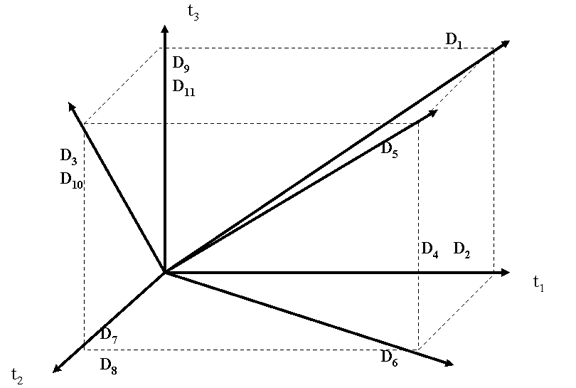
We will use this notation when we calculate the weightings on the terms in document and query vectors and the similarity of documents represented as vectors

We'll encounter cosines when we compute the similarity of documents and queries in terms of the "distance" between their vectors
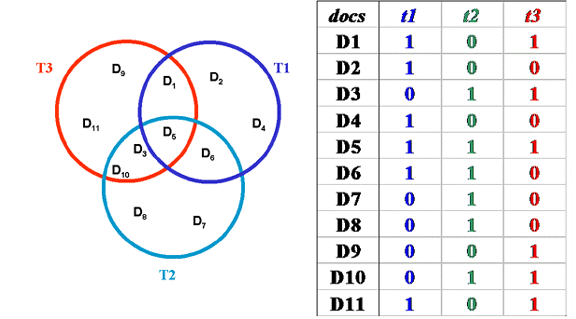
We can create a matrix in which we represent for each document the frequency of the words (or terms created by stemming morphologically related words) that it contains
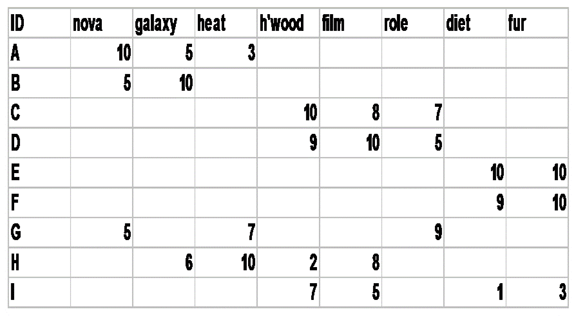


We can use this same matrix to think of the meaning of a word / terms as a vector whose coordinates measure how much the word indicates the concept or context of a document

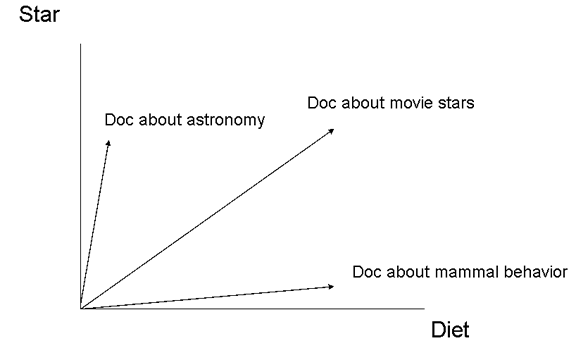
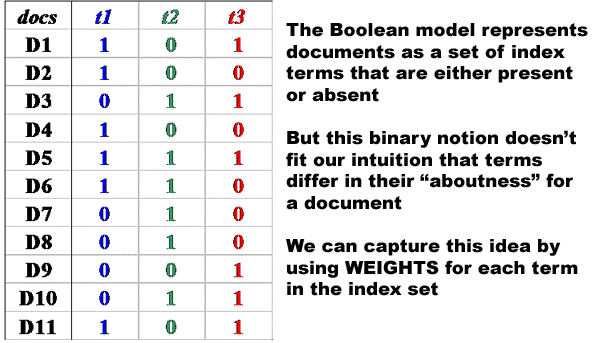
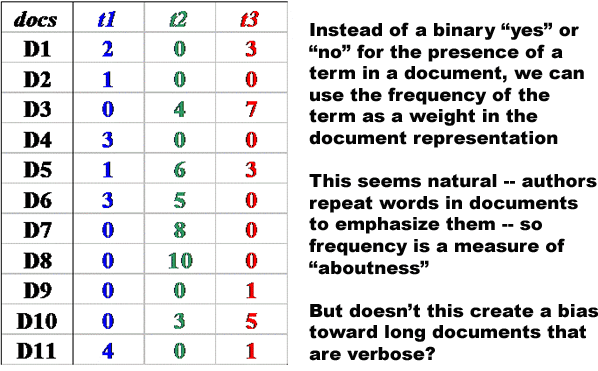
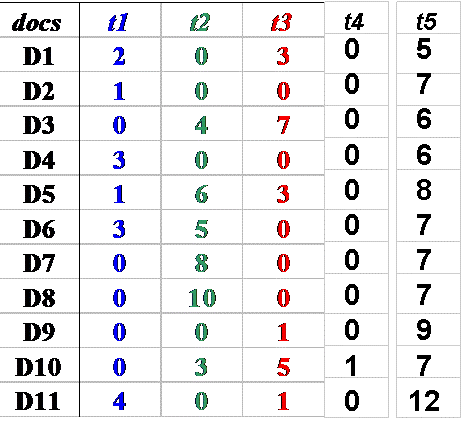


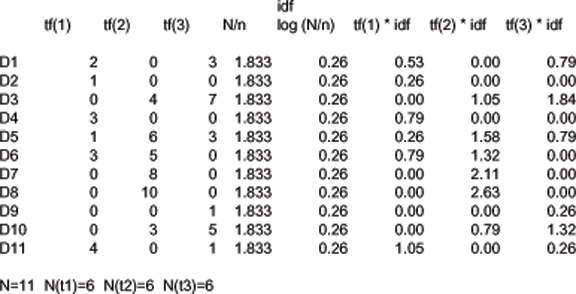
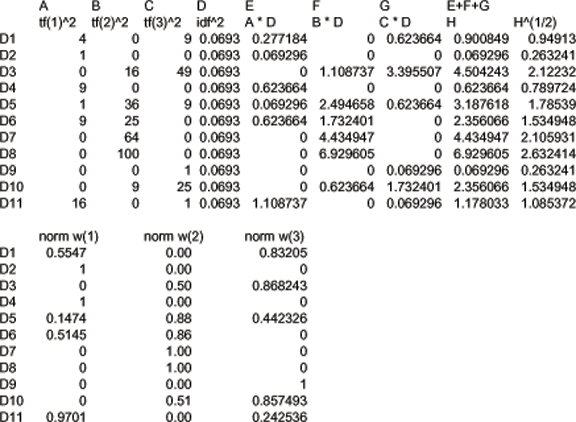
Using the matrix from the "Weighting Using Term Frequency" slide a few slides back
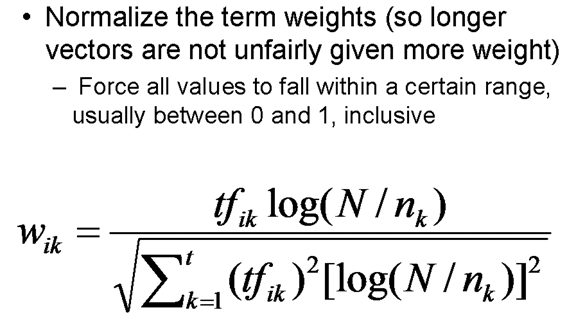
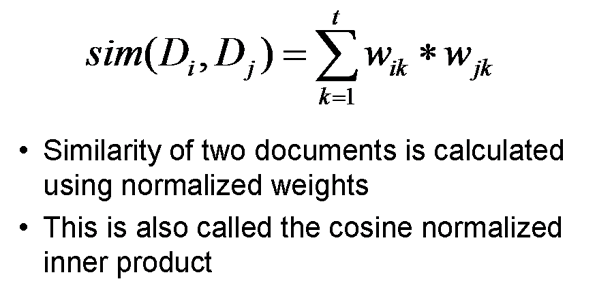

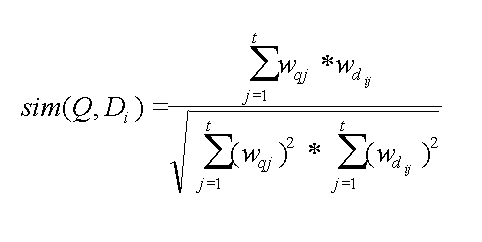
If the weights are not already normalized, we can combine the normalization and the similarity calculation using this equation